{kind=link}
כל הזכויות שמורות לטל בן שושן – Shushan.co.il
RegEx הוא קיצור של Regular Expression, ביטוי רגולרי הוא רצף של תווים בחיפוש מחרוזות, בעזרת RegEx נוכל לבצע חיפוש בתוך מסמך ובכך לאתר בדיוק את מה שאנחנו מחפשים, זה יכול להיות כתובות IP בתוך מסמך מבולגן עם מלא טקסט, זה יכול להיות אתר שבודק כתובת אימייל שמחייב שיהיה @ בין 2 רצפים.
ניתן לבדוק עוד הרבה דברים ב RegEx ובמאמר זה נלמד איך לבצע את החיפושים האלו.
אני אשתמש באתר
https://www.regexpal.com ובאתר
https://gchq.github.io/CyberChef
חיפוש אותיות – Literal Match
באמצעות אתרים אלו ניתן לבצע חיפושים בתוך טקסט שתכניסו לו.
באתר יש לרשום ב Test String את הטקסט שאני רושם וכך למעשה תוכלו לתרגל
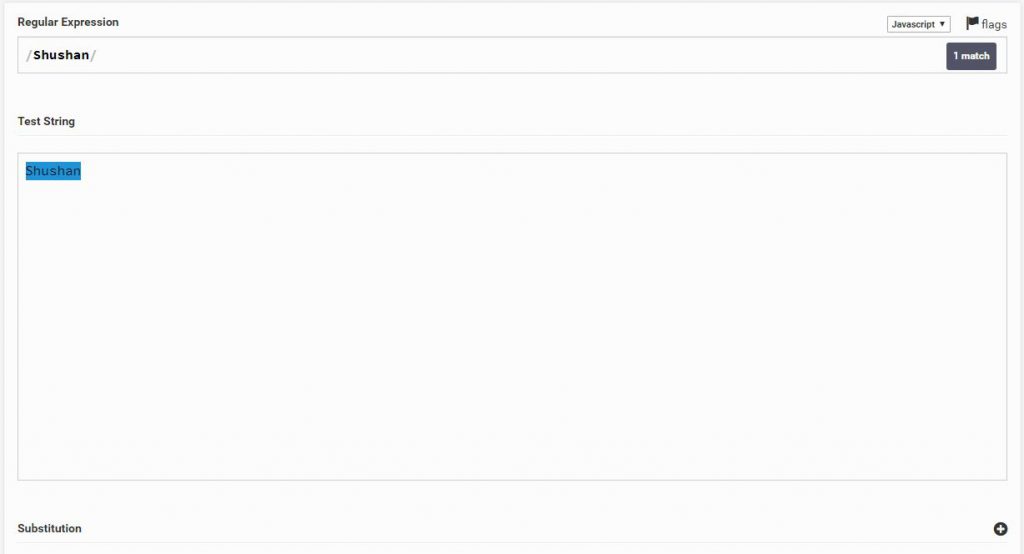
נתחיל מהפשוט ביותר, אם אני רוצה לחפש טקסט כמו Shushan, אני פשוט אזין Shushan בחיפוש
הבחינו כי RegEx רגיש לאותיות קטנות וגדולות
Regular Expression
Shushan
Text String
Shushan
חיפוש מספרים
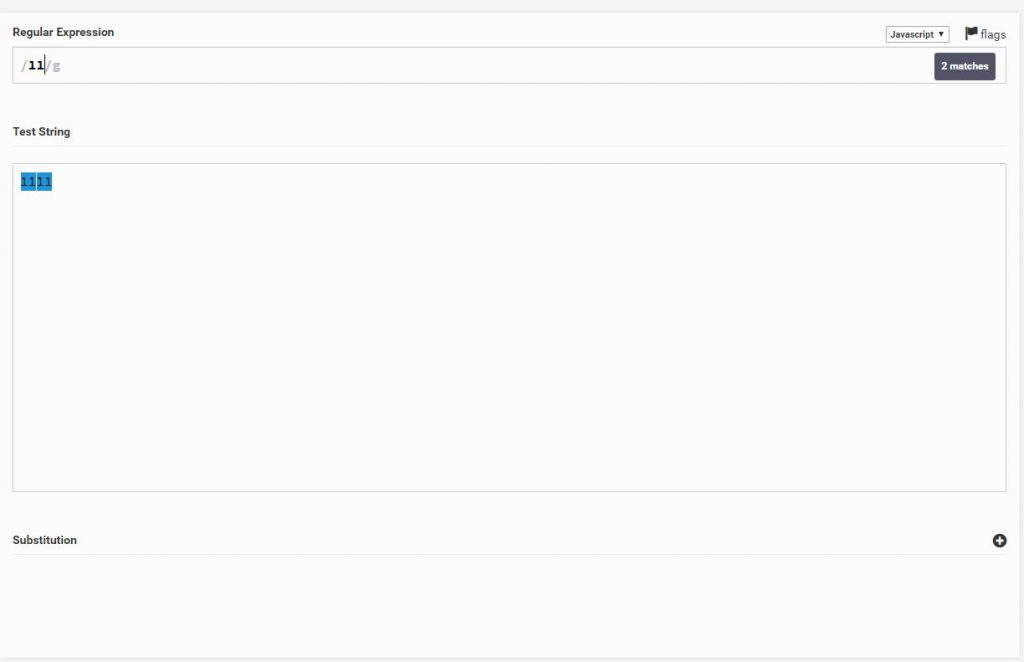
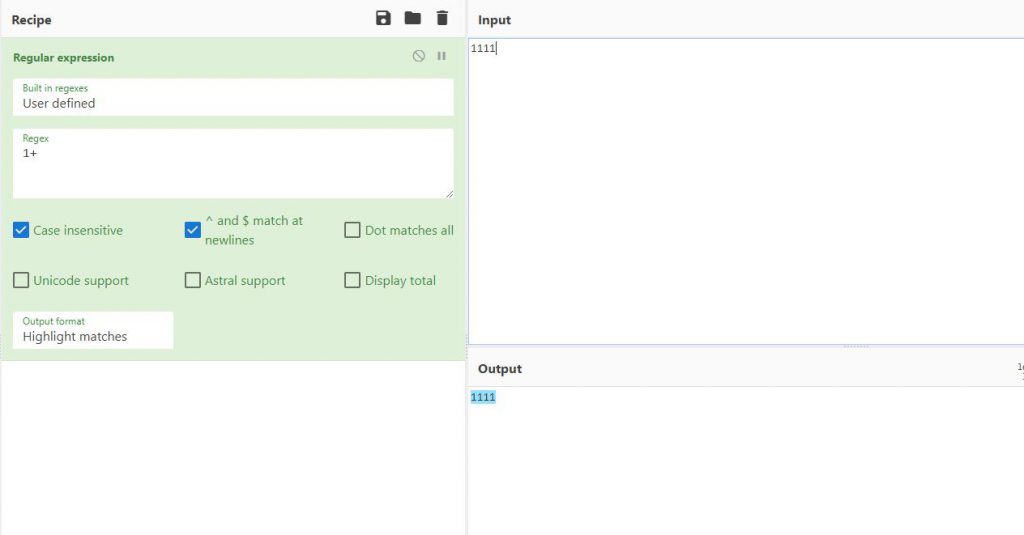
כאשר אני מזין 11 הוא מחפש את הרצף 11 בכל מקום שהוא מופיע, ניתן להבחין שגם כאשר רשום 1111 הוא מצא 2 התאמות שהם 11 ו11 למרות שהם כתובים ברצף
Regular Expression
1111
Text String
1111
חיפוש בתוך [ ] סוגריים – Character Class
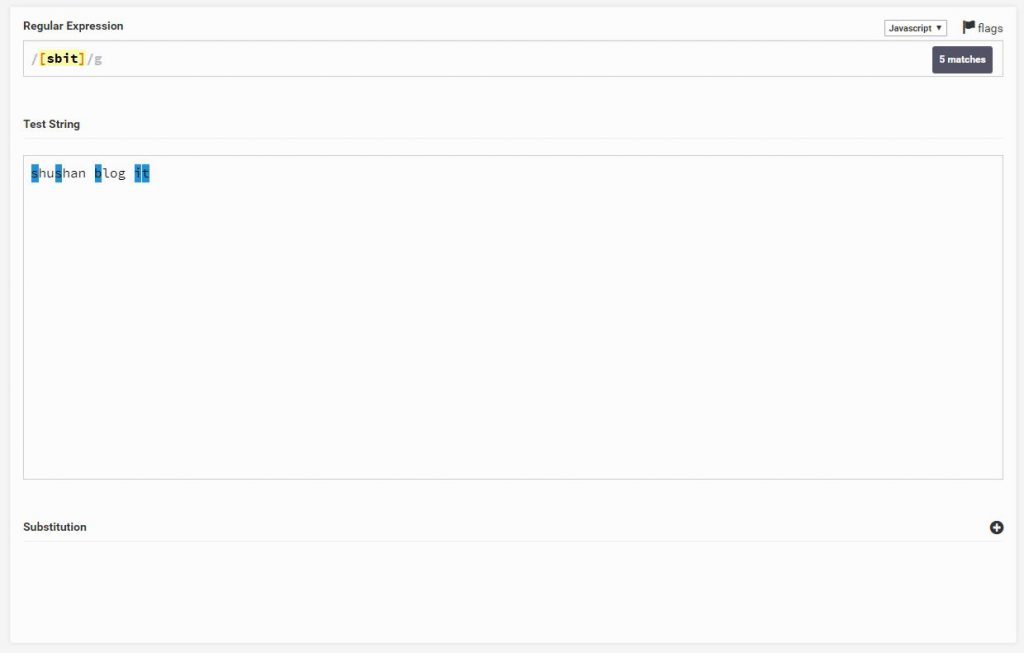
חיפוש בתוך סוגרים נותן לנו את האפשרות לחפש אובייקט אחד בתוך הרשימה
ניתן להבחין שרשמנו sbit והוא הדגיש לנו את כל האותיות המופיעות ב Text String
Regular Expression
[sbit]
Text String
shushan blog it
כעת נבדוק אם נוכל למצוא רצף של מספרים או אותיות.
אם נקיש [a-m] נקבל סימון של האותיות מa עד m
Regular Expression
[a-m]
Text String
abcdefghijklmnopqrstuvwxyz
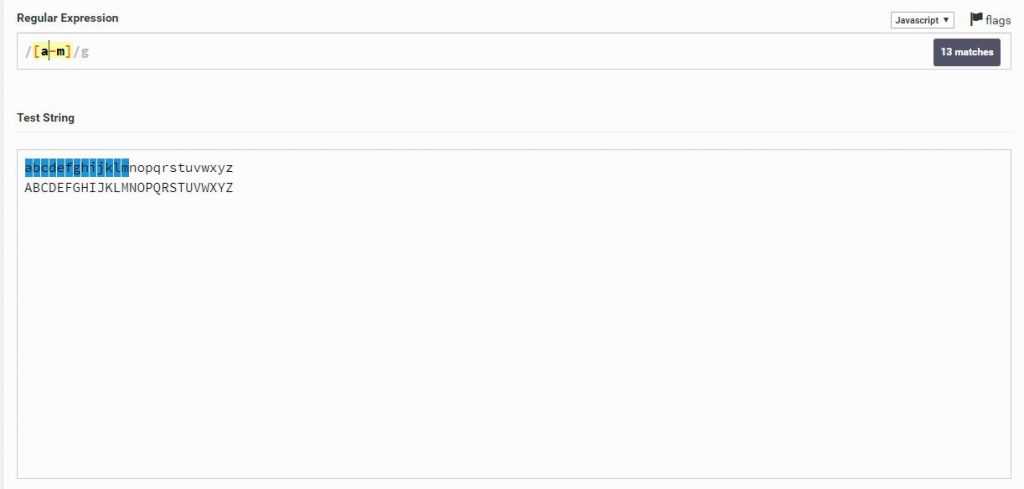
ניתן להבחין שברגע שהכנסתי אותיות גדולות הוא לא מסמן אותן ( כמו שרשמתי, הוא רגיש לאותיות קטנות וגדולות)
Regular Expression
[a-m]
Text String
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
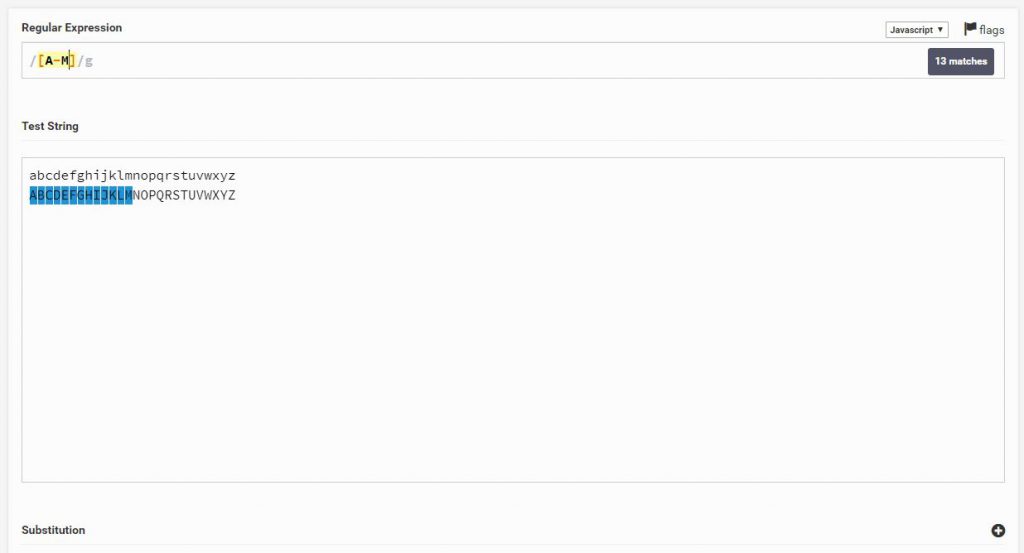
אם הייתי רוצה לחפש גם a-m באותיות גדולות וקטנות הייתי רושם כך
Regular Expression
[A-Ma-m]
Text String
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
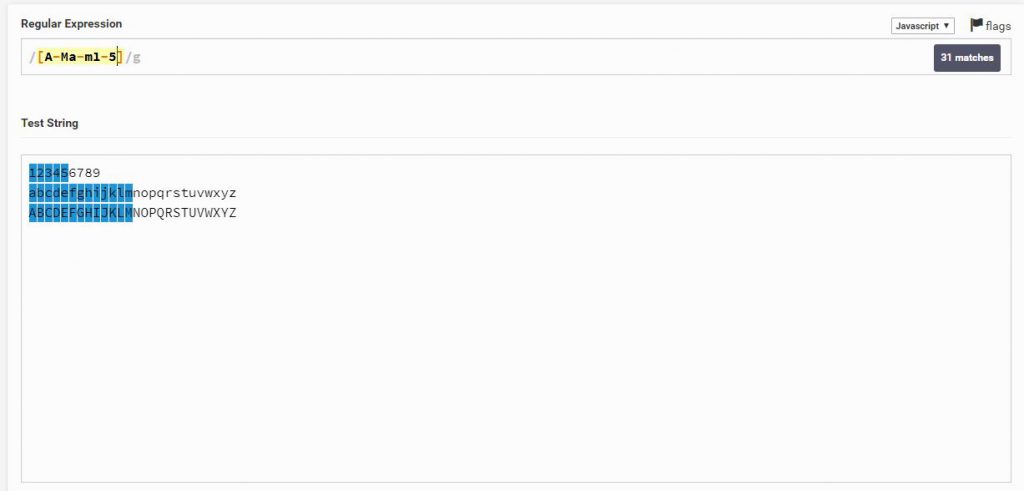
גם מספרים, אפשר להוסיף
Regular Expression
[A-Ma-m1-5]
Text String
123456789
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
^ – Negate
ב Regex כמו גם כן במערכות אחרות Negate הוא – שלילה, זאת אומרת שנוכל לשלול חיפוש מסוים, לדוגמה
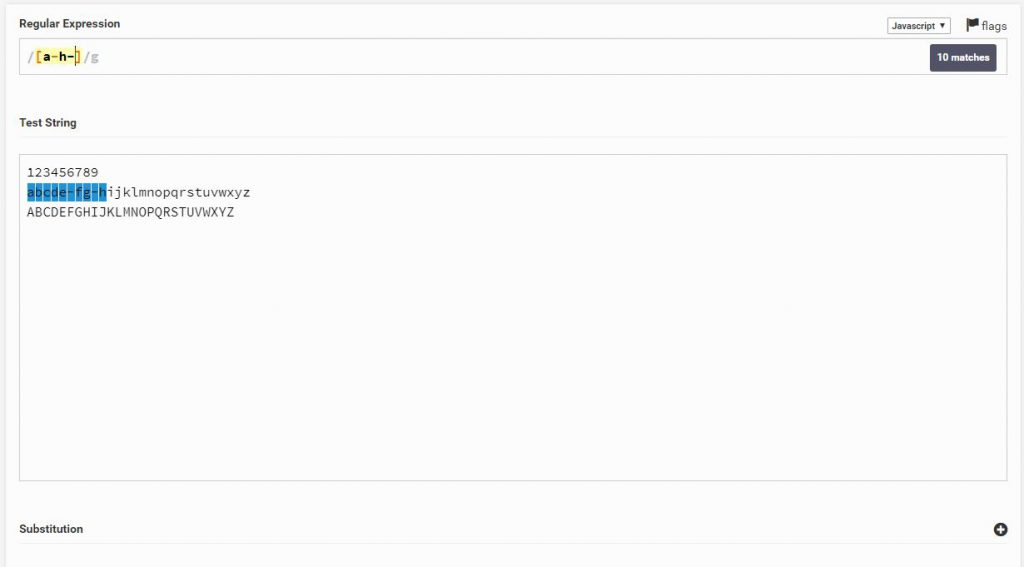
אני רוצה שהוא לא יחפש את האותיות a-h ואת כל השאר כן יסמן, אני אבצע זאת על ידי Negate
אם ^ יהיה בסוף ולא בהתחלה כמו פה, אז המערכת תחפש את הסימן ^ ולא יהיה לו כל משמעות.
Regular Expression
[^a-h]
Text String
123456789
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
\ – Escapes Special Character
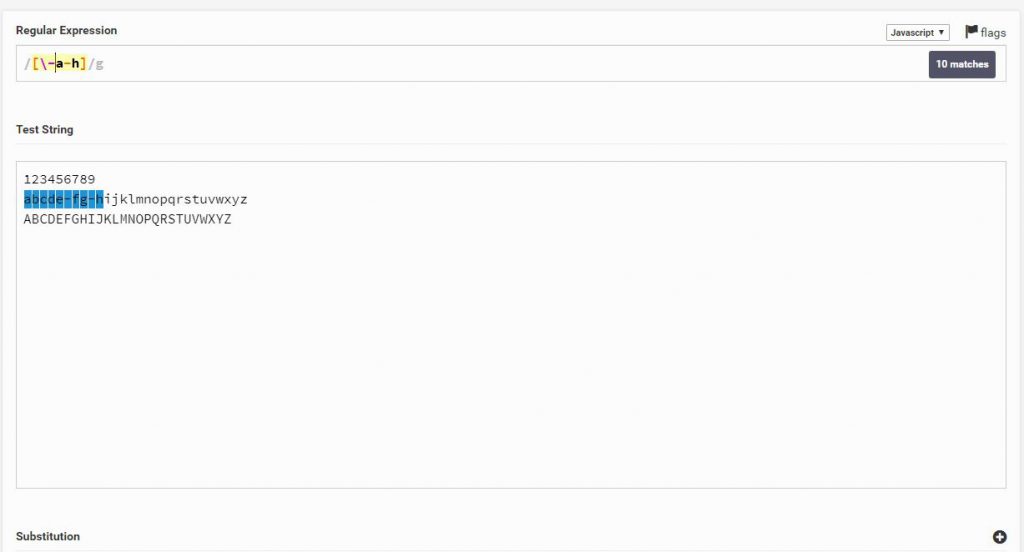
כאשר נרצה לחפש נאמר את הסימן -, מה נוכל לעשות? על מנת לבטל את המשמעות של – (שהוא מ.. עד..) נשתמש ב \ שהוא יבטל את "המיוחדות" של התו – ובכך Regex יחפש – בטקסט
Regular Expression
[\-]
Text String
123456789
abcde-fg-hijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
אופציה נוספת היא להכניס את ה- בסוף וכך הוא לא מיוחד
Alternation / Operand
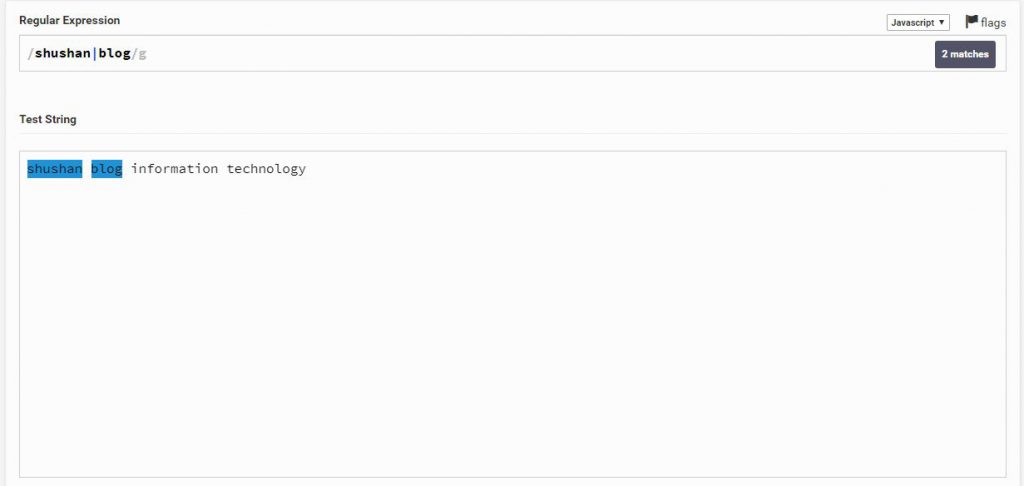
שיטה זו ע"י הוספת | אומרת שRegex יבדוק תחילה את הביטוי משמאל ואם ימצא או לא ימצא הוא יעבור לביטוי הבא אחרי ה|.
Regular Expression
shushan | blog
Text String
shushan blog information technology
Characters & MetaCharacters
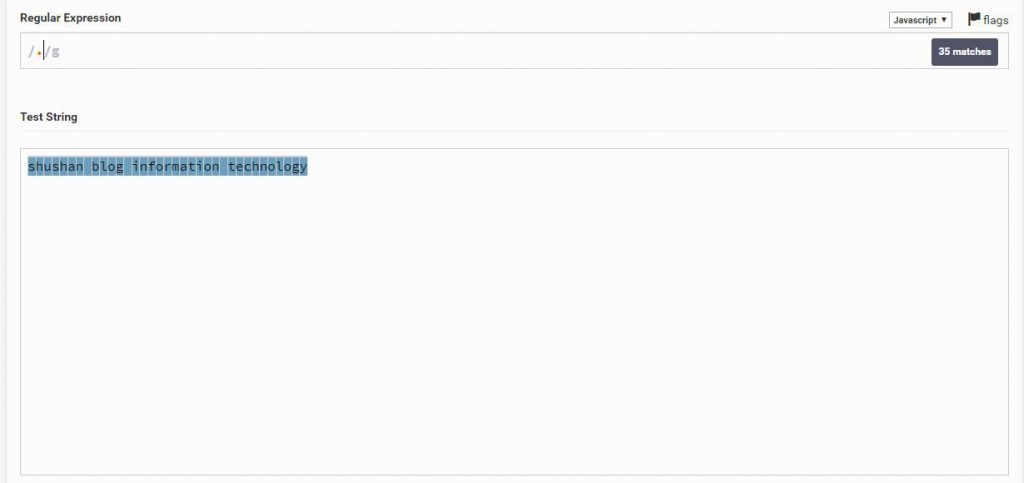
על ידי הוספת \ ואז אות מסויימת, נוכל להפוך את החיפוש ליותר מיוחד
לדוגמה הזו הוספתי רק . זה אומר להציג את כל הטקסט הקיים
Regular Expression
.
Text String
shushan blog information technology.
1234567890
!@#$%^&*()
Tal Ben Shushan
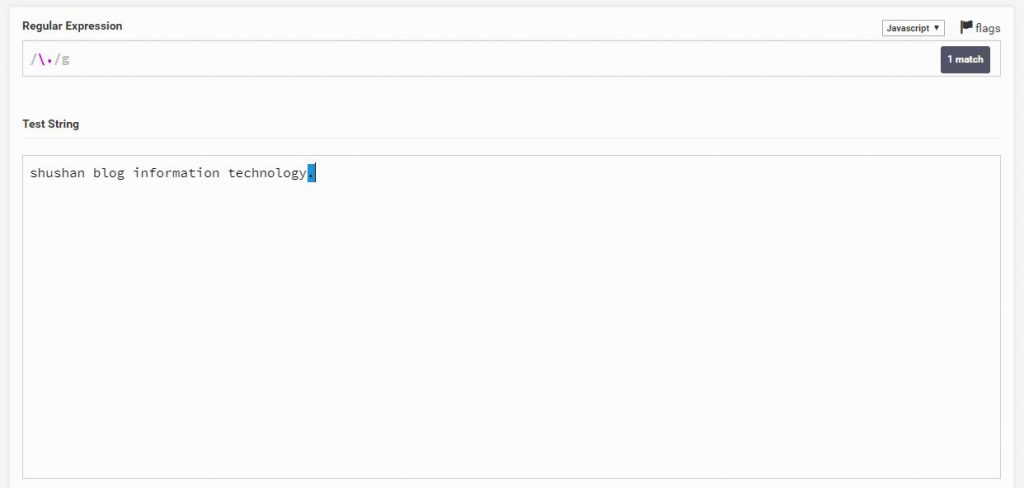
אבל אם אני אוסיף .\ זה אומר לו למצוא רק נקודה .
\
\ ואז רווח, הוא יאתר רק רווחים
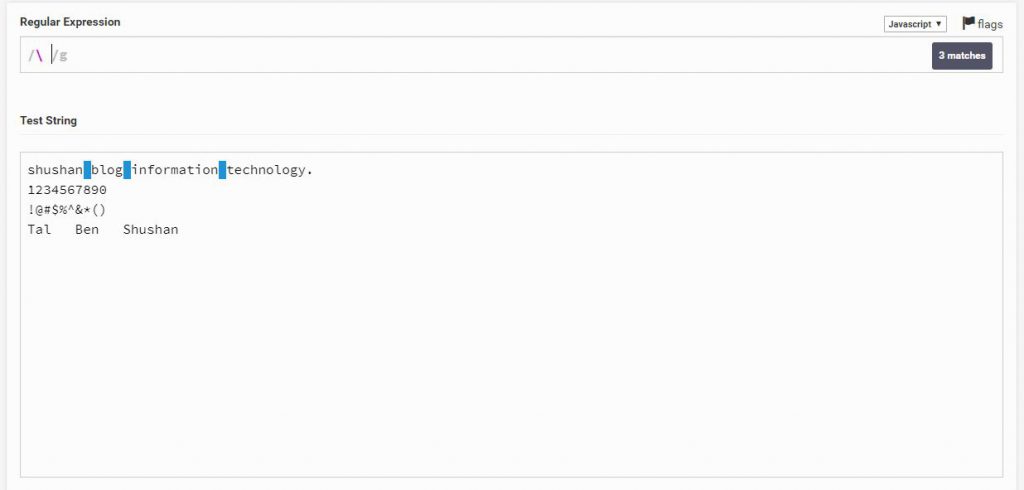
w\
w\ – הוא חיפוש של אותיות בלבד, זאת אומרת ללא מספרים או סימנים והאות מעידה על כך, words
Regular Expression
\w
Text String
shushan blog information technology.
1234567890
!@#$%^&*()
Tal Ben Shushan
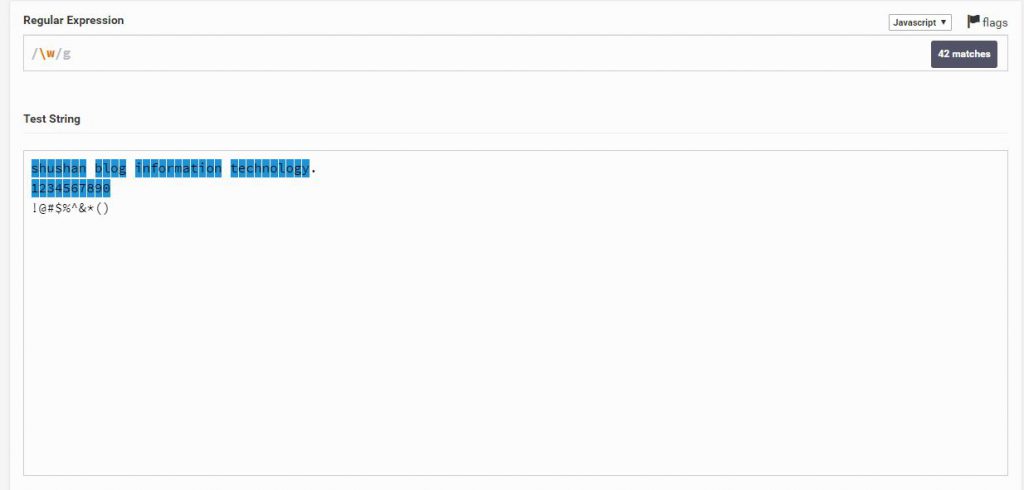
W\
אבל מה קורה כאשר נקיש W גדולה? W\
RegEx יסמן את כל מה שהוא לא אותיות ומספרים! הוא בעצם יסמן רווחים,נקודות, סימנים
Regular Expression
\W
Text String
shushan blog information technology.
1234567890
!@#$%^&*()
Tal Ben Shushan
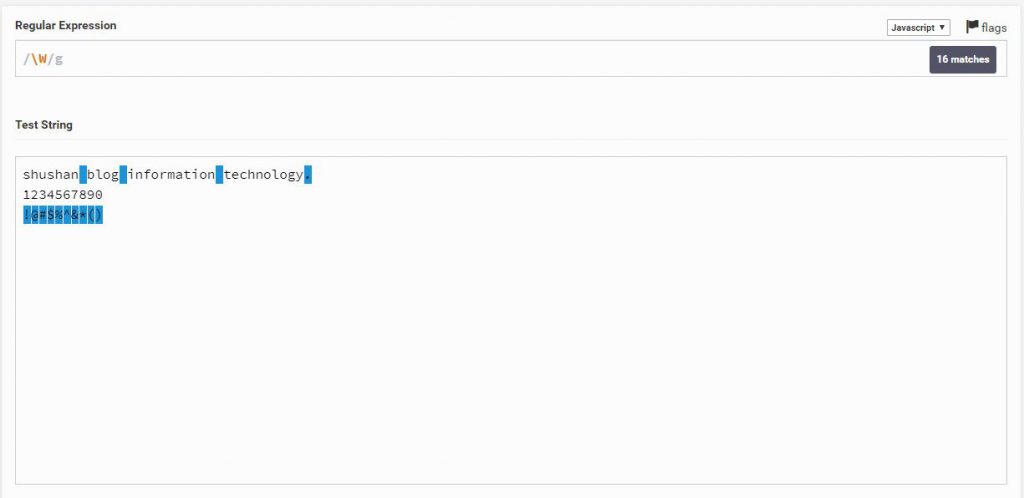
d\
ואיך נסמן מספרים בלבד? על ידי d\ שאומר Digits
Regular Expression
\d
Text String
shushan blog information technology.
1234567890
!@#$%^&*()
Tal Ben Shushan
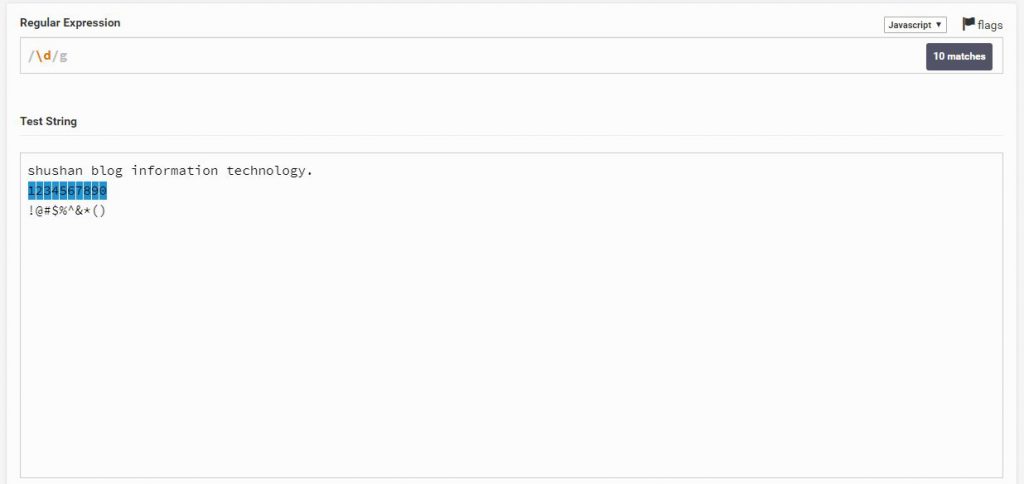
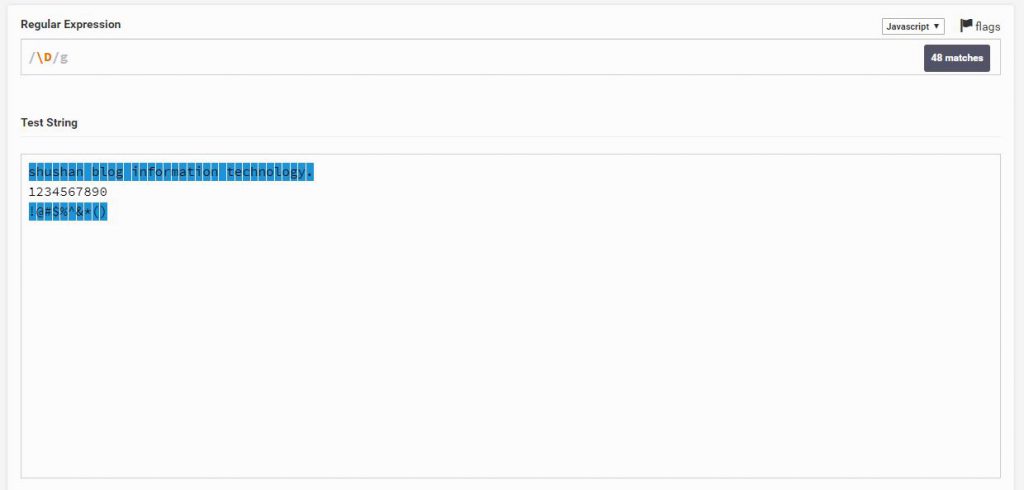
D\
ומה לדעתם יעשה D\ גדול? הוא יסמן את כל מה שהוא לא מספרים.
Regular Expression
\D
t\
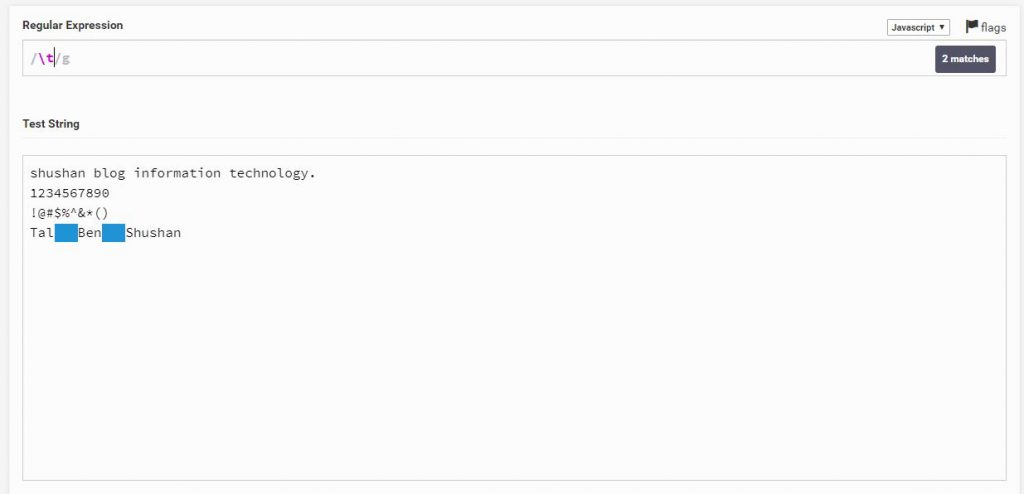
כעת נבדוק כיצד נסמן Tab (רווח ארוך) זאת על ידי t\
Regular Expression
\t
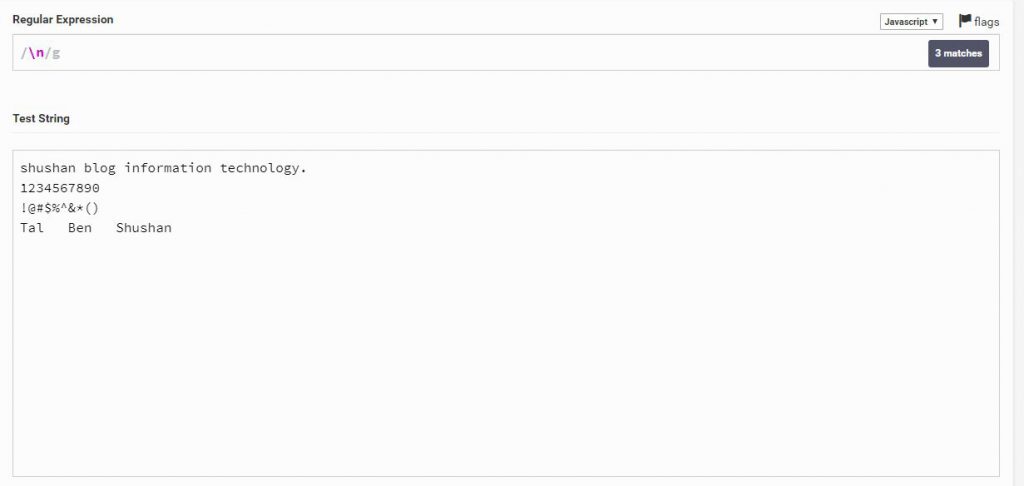
n\
הוא למעשה יסמן לנו רק רווחים רגילים, הבחינו כי הוא מצא 3 Matches, הוןא לא מציג את זה בגלל התוכנה \ אתר וכמובן שלא את השם Tal Ben Shushan כי מה שיש שם זה לא רווח זה Tab
Regular Expression
\n
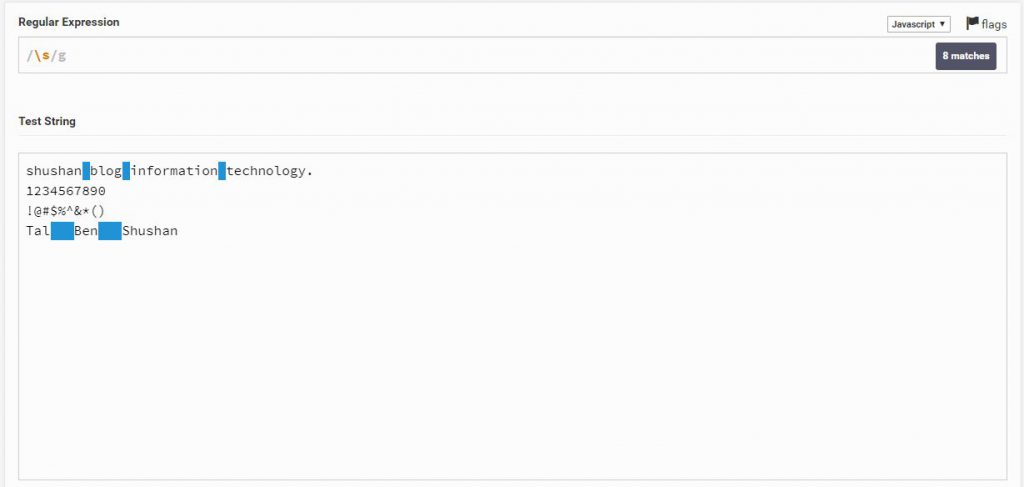
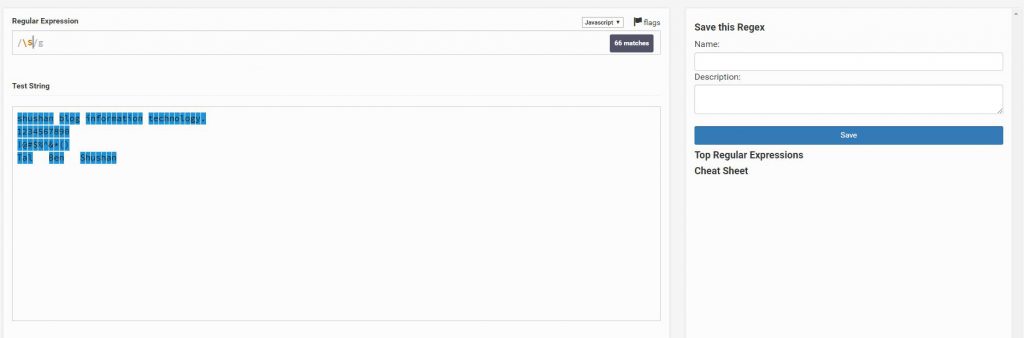
s\
הוא למעשה יסמן את כל מה שהוא אינו אותיות,מספרים וסימנים ולכן נשאר רק הרווחים והTab
Regular Expression
\s
S\
מה יקרה כאשר נבצע S\ עם S גדולה, הוא יסמן כל מה שהוא לא רווחים ו Tab
Regular Expression
\S
b\
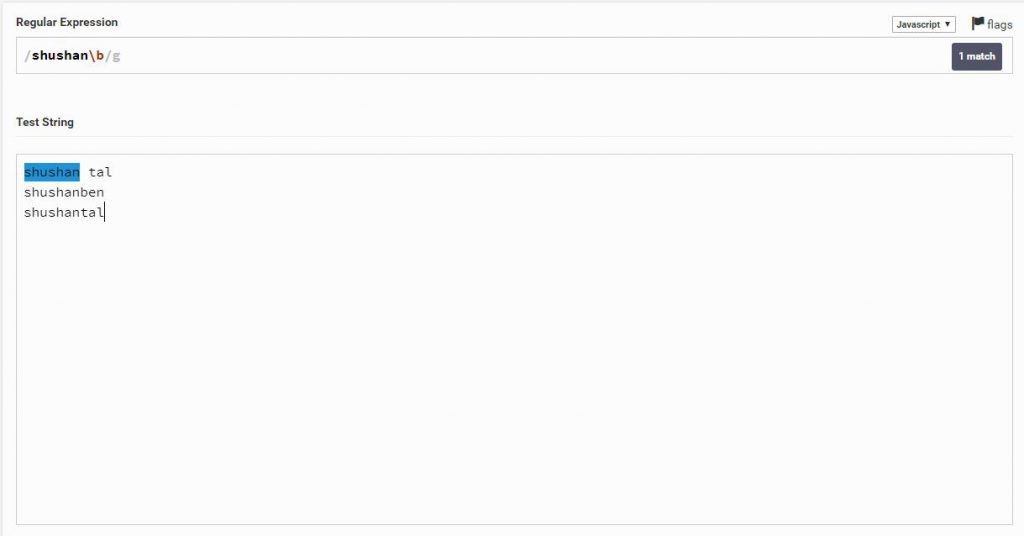
הוא סימון של מילה רק כאשר היא בודדת
Quantifiers
.
נקודה, מסמן רצף של מה שרוצים (לא כולל רווחים)
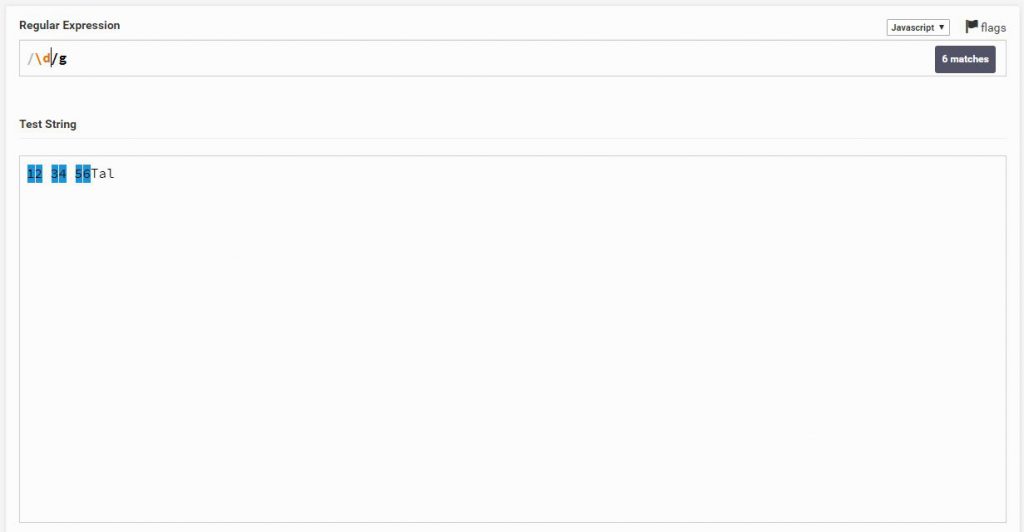
נניח נחפש רק מספרים, ניתן להבחין שהוא מסמן את המספרים בבודדים
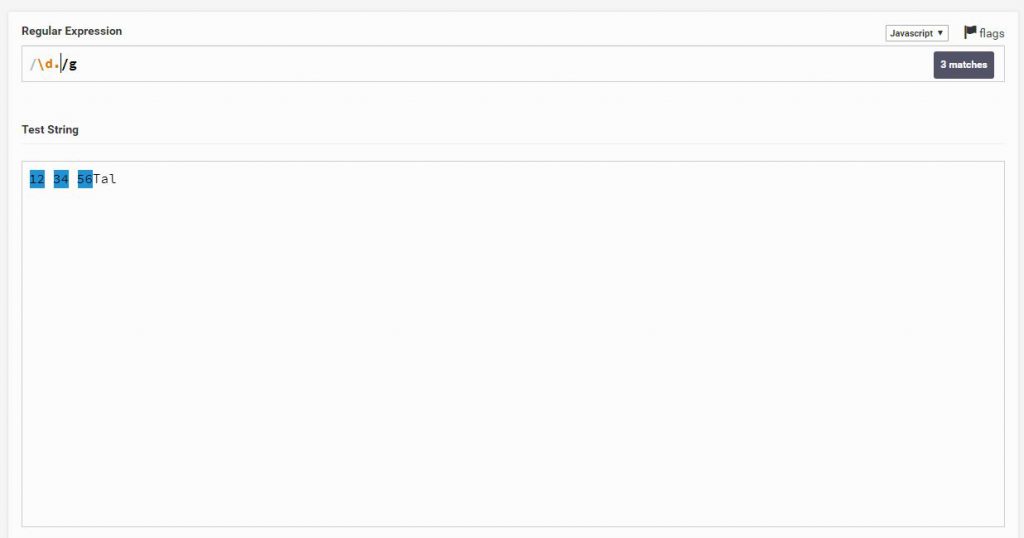
אם נסמן עם . נקבל את המספרים עצמם ביחד אך עם רווח (. לא מסמן רווח)
+
הוא למעשה אובייקט (אות או מספר) אחד או יותר. זאת אומרת שאפשר לכתוב התחלה של משפט שיודעים שהשורה שרוצים מתחילה ואז + ואז הוא יסמן את כל ההמשך אוטומטית (הסימון הוא שלם ולא אות אות)
כמו בתמונה הבאה, סימנתי לו לסמן את כל [a-z] אבל הוא סימן אותם אות אות אז הוספתי את +, והתוצאה
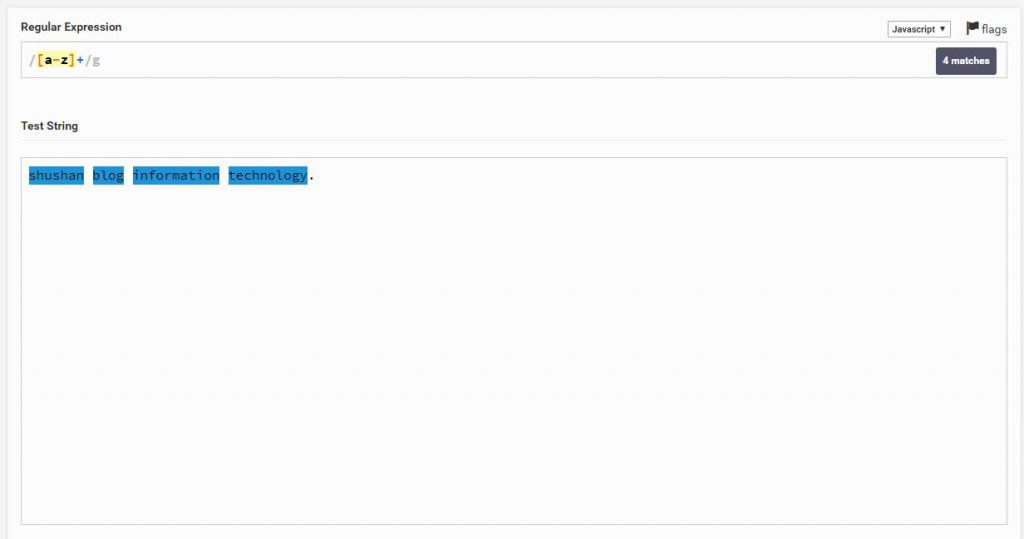
או 1 עם + שכן המספר 1 פעם אחת או יותר
או למשל הגדרה הבאה, בה רציתי לסמן את כל המספרים (אבל לא מספר מספר)
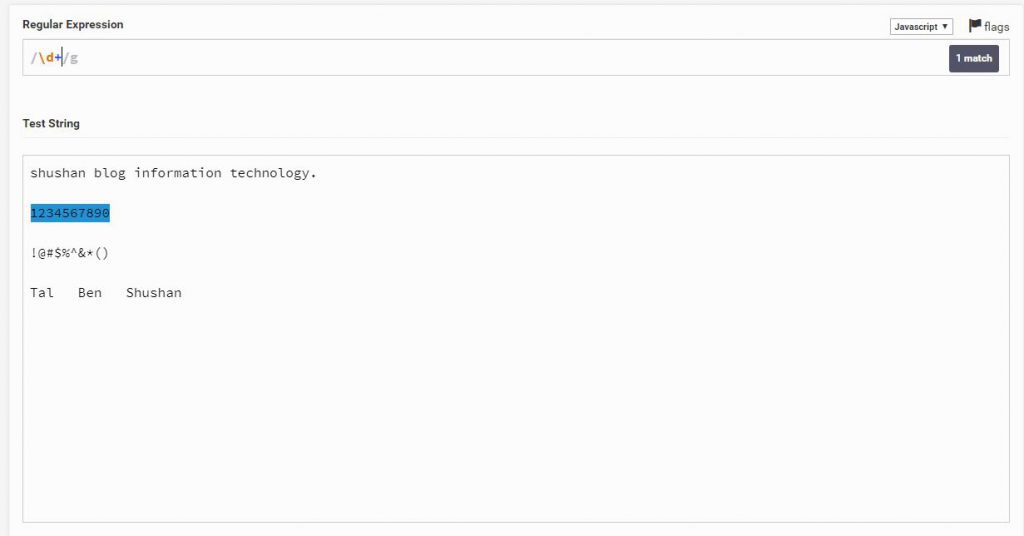
הפעם השתמשתי ב
https://gchq.github.io/CyberChef/
תוכלו להבחין, שהוא סימן את כל מה שבא אחרי http (על ? סימן שאלה נסביר בהמשך)
Text String
https://shushan.co.il
https://www.shushan.co.il
https?:\/.+
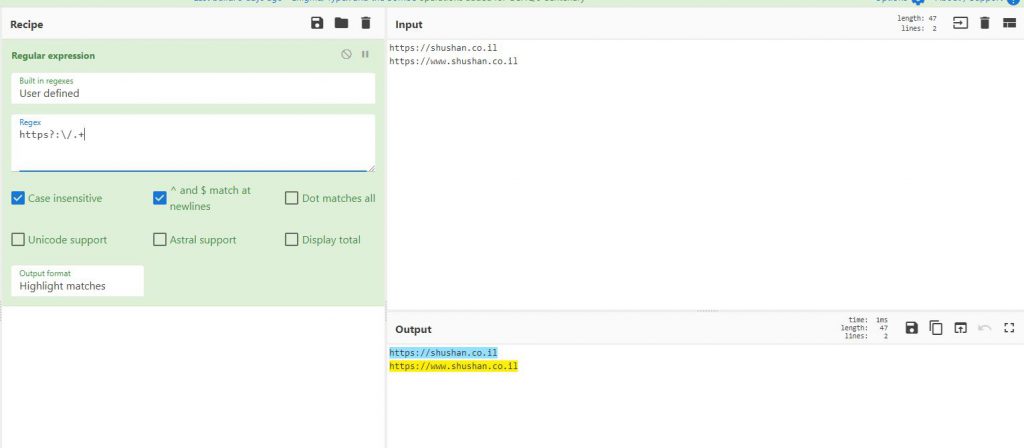
גם להוסיף * יתן לנו את האפקט הרצוי
https?:\/.*
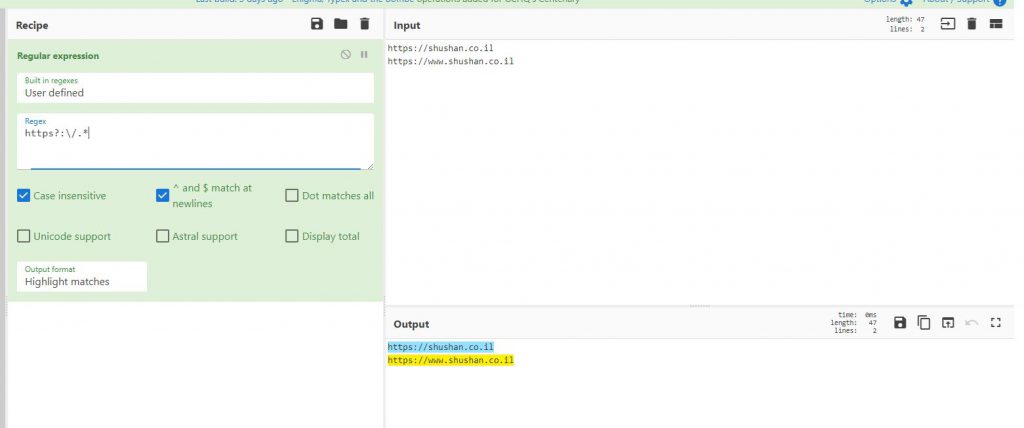
?
סימן שאלה הוא האופציה להגדיר שהאות שבאה לפניו יכולה להופיע או יכולה לא להופיע, בדיוק כמו פה
יש http ויש https, לכן ה s יכולה להופיע ויכולה לא להופיע ולכן הוא מסמן הכל.
ה\ הוא בשביל לבטל את המיוחדות של / וה* זה בשביל לסמן את כל מה שבא אחריו.
Text String
https://shushan.co.il
https://www.shushan.co.il
Regular Expression
https?:\/.*
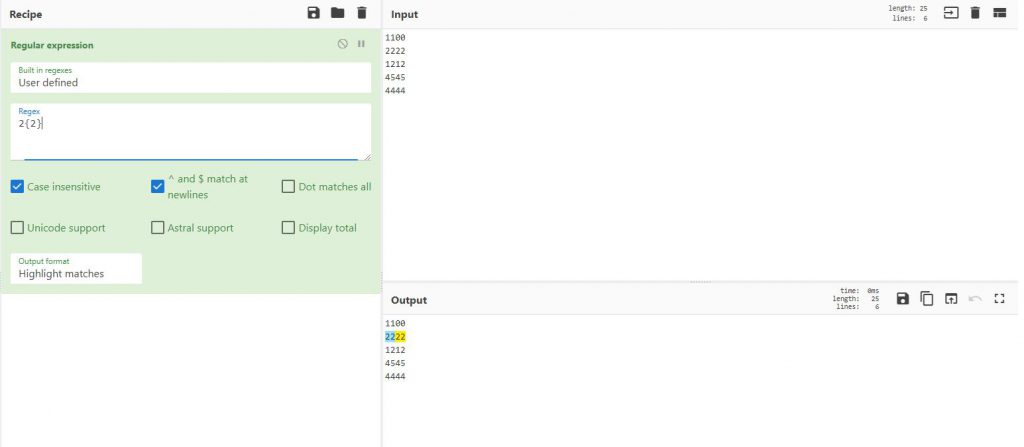
{}
סוגריים מסולסלות – כמה פעמים האובייקט שרשמתם מופיע
למשל כאן, אני רוצה לסמן 2 שמופיע פעמיים, אז Regex יסמן לי 22 ואז שוב 22
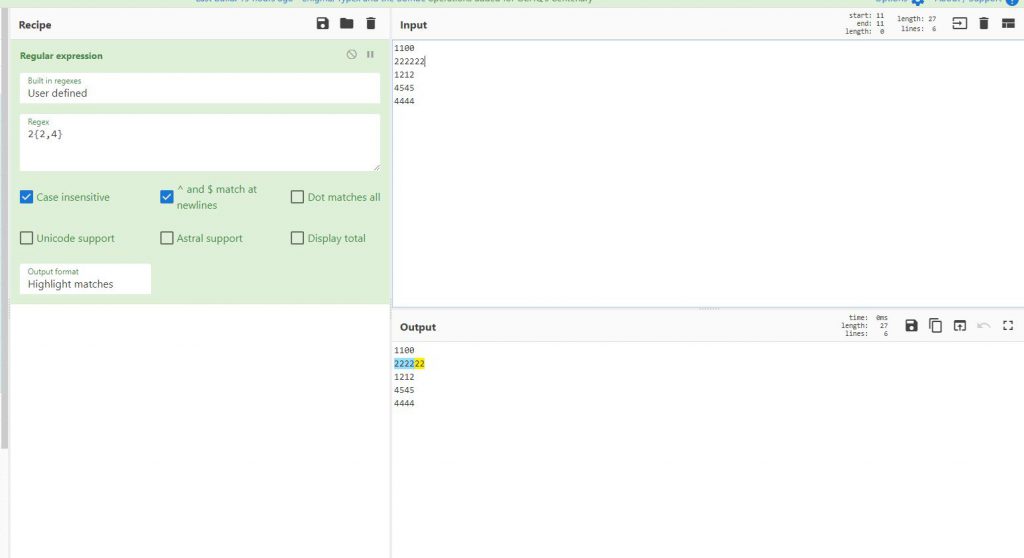
כאן אני יכול לסמן לו ש2,4 בתוך סוגריים מסולסלות ויסמן לי 4 פעמים 2, כיוון ש2 מופיע 4 פעמים, ואילו ה2 הנוספים הוא יסמן כיוון שסימנתי לו ש2 מופיע פעמיים או ארבע פעמים
זאת אומרת שה, מסמן לו כמה פעמים יופיע 2 והוא יסמן אותם
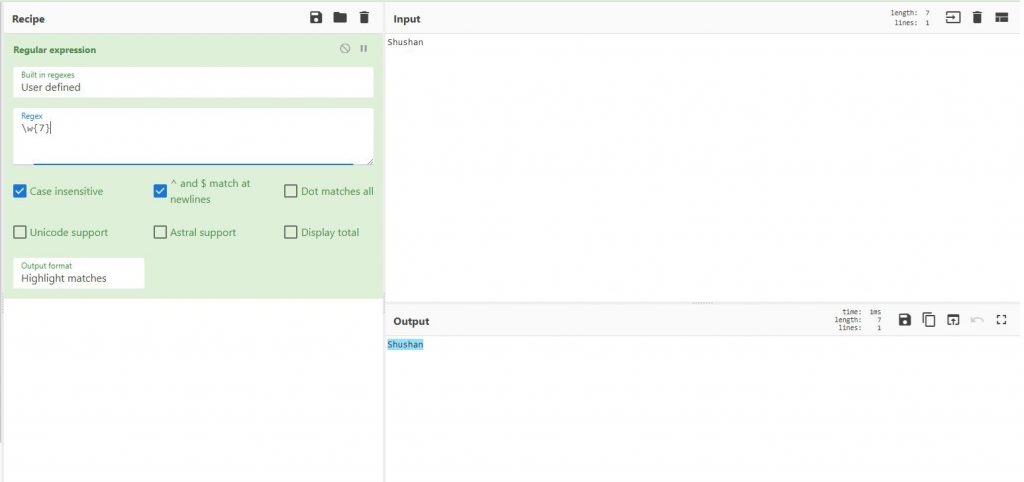
למשל בדוגמה הבאה נוכל לסמן לו שאות מופיע 7 פעמים אז הוא יסמן את כל השם Shushan
()
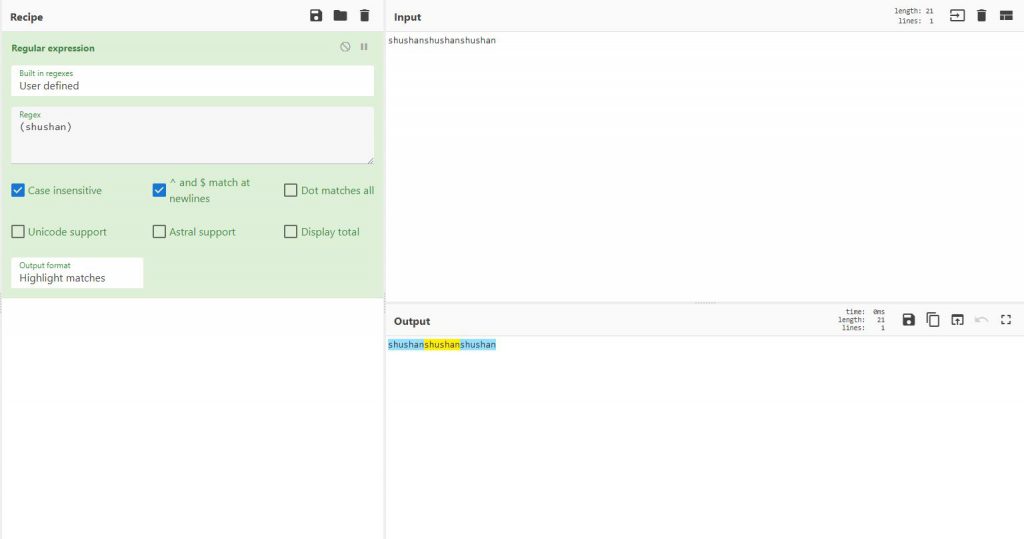
סוגריים – קבוצה, זאת אומרת שהוא יחפש ויתפוס את האוייבקט שרשתם כקבוצה
למשל כאן, ניתן להבחין שהוא תפס את המילה shushan ויש אותה 3 פעמים.
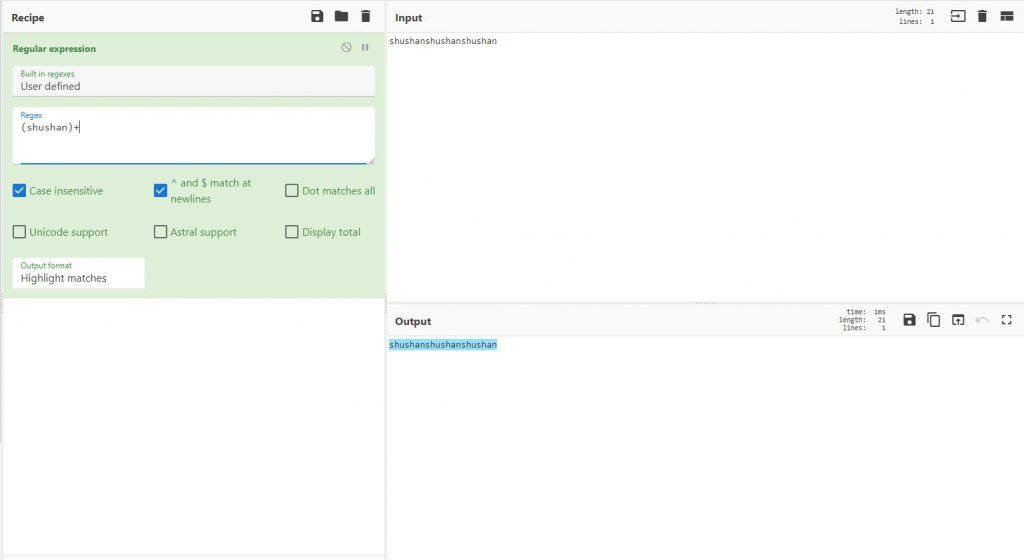
אם אני אשתמש בסימן + בסוף הוא יסמן את כולם, שכן ה+ הוא המילה פעם אחת או יותר
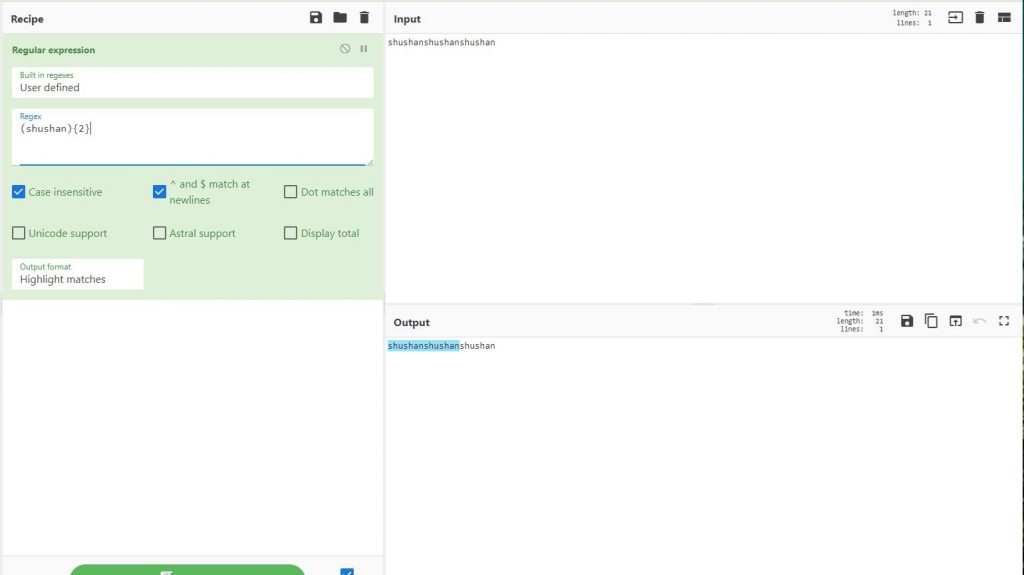
גם סוגריים מסולסלות עם כמה פעמים מופיע shushan, הוא יסמן
Lookarounds
על ידי Lookarounds אפשר לחפש מילה ואז רק אם יש מילה מסוימת אחרי הוא יציג אותה
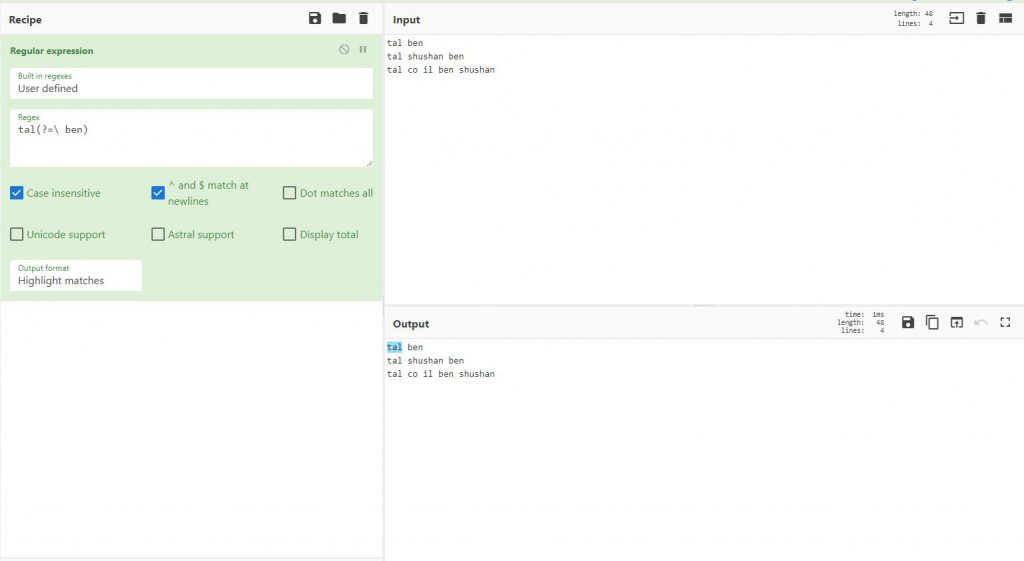
Positive lookahead
בדוגמה הבאה נוכל להבחין שאני רוצה שהוא יציג לי את המילה tal רק אם יש אחריה ben
tal(?=\ ben)
Negative lookahead
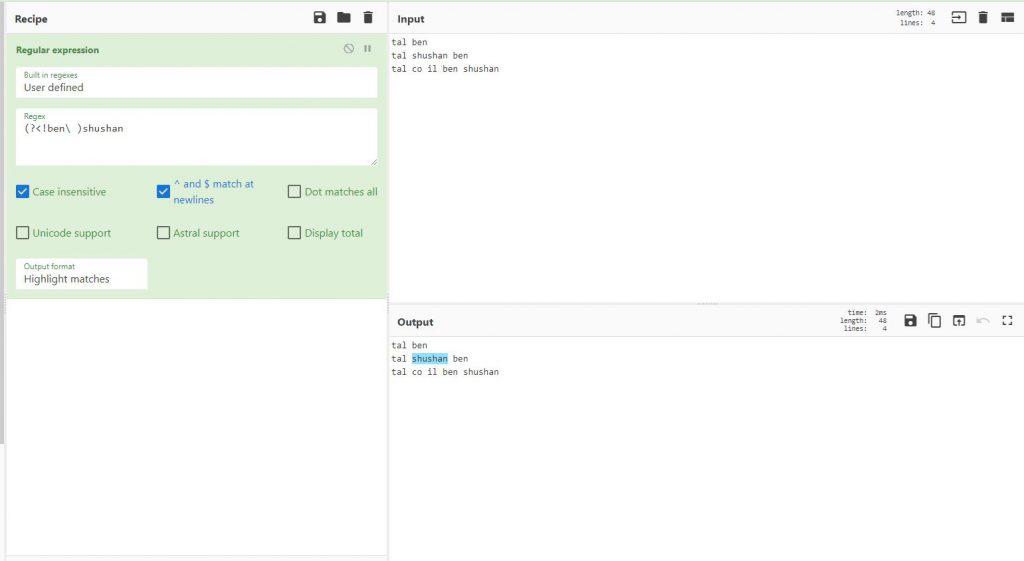
ברגע שאנחנו רוצים שהוא יסמן את כל ה tal אבל שאין אחריהם ben אז נשתמש ב!
tal(?!\ ben)
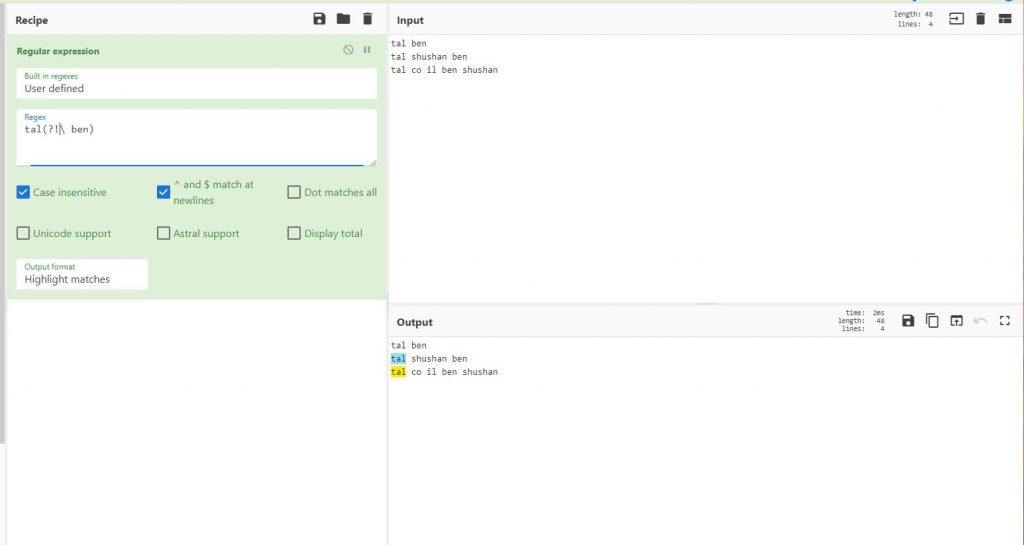
Positive lookbehind
בצורה זו נוכל להציג למשל לסמן את shusan רק אם בא לפניו המילה ben
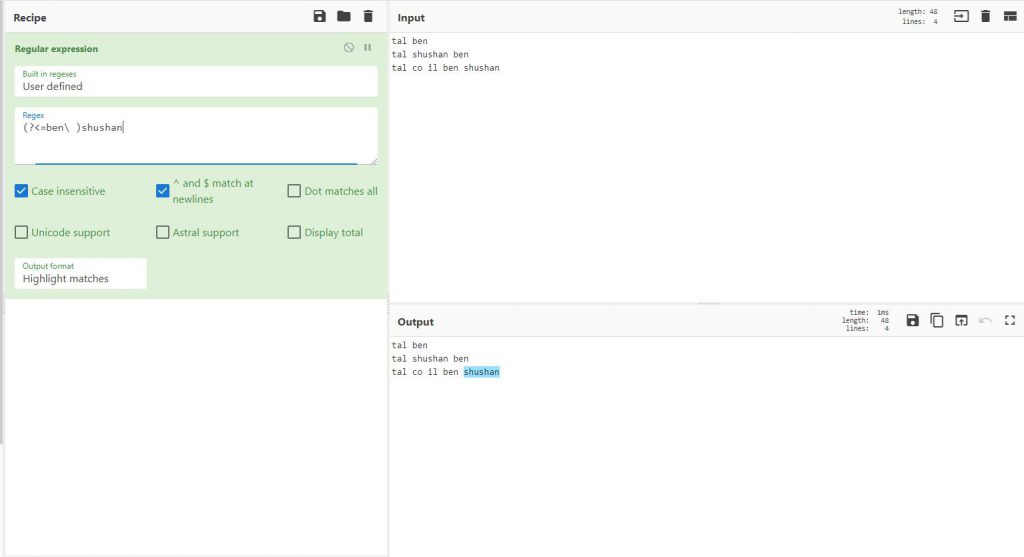
Negative lookbehind
בצורה זו כמו מקודם נוכל לסמן את כל מקום שמופיע shushan ולפניו אין ben
Anchor
^
מסמלים את האות או המילה בהתחלה או בסוף על ידי הנחת ^ בתחילת ה Regex
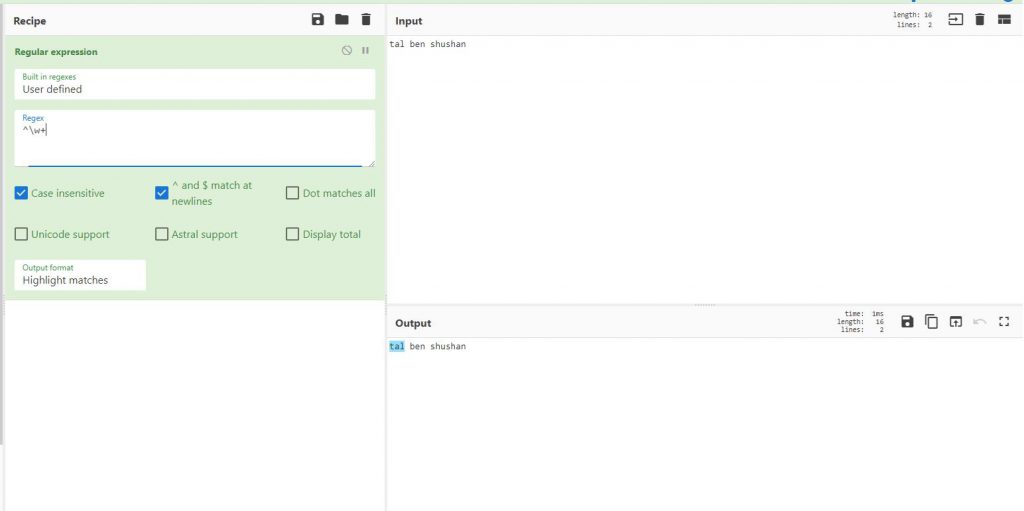
דוגמה בה אני רוצה לסמן אות ואז + בשביל לסמן את כל המילה, אבל אני רוצה רק את המילה הראשונה
אני אבצע זאת כך
^\w+
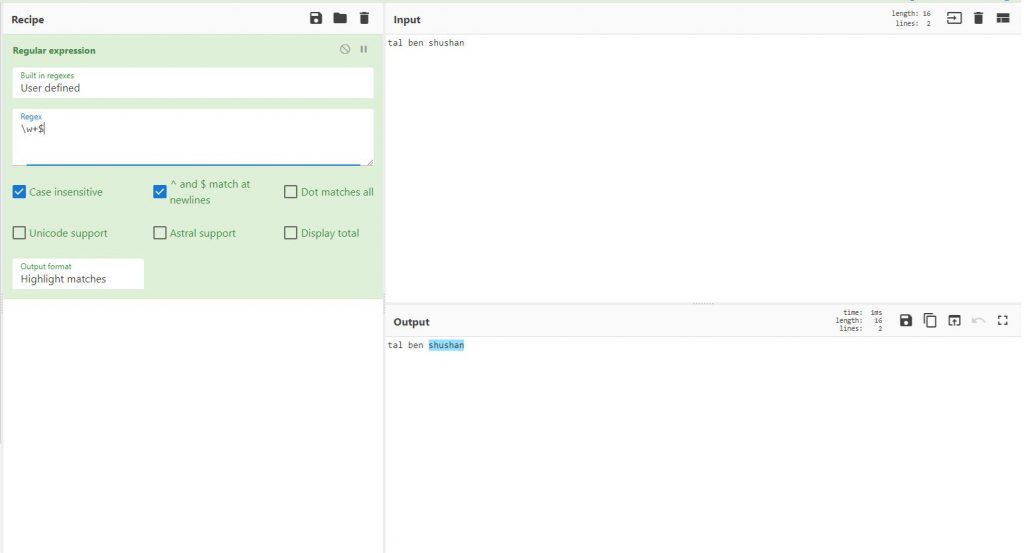
$
סימן הדולר הוא להגדיר שהאות או המילה בסוף אותה נרצה לסמן
\w+$
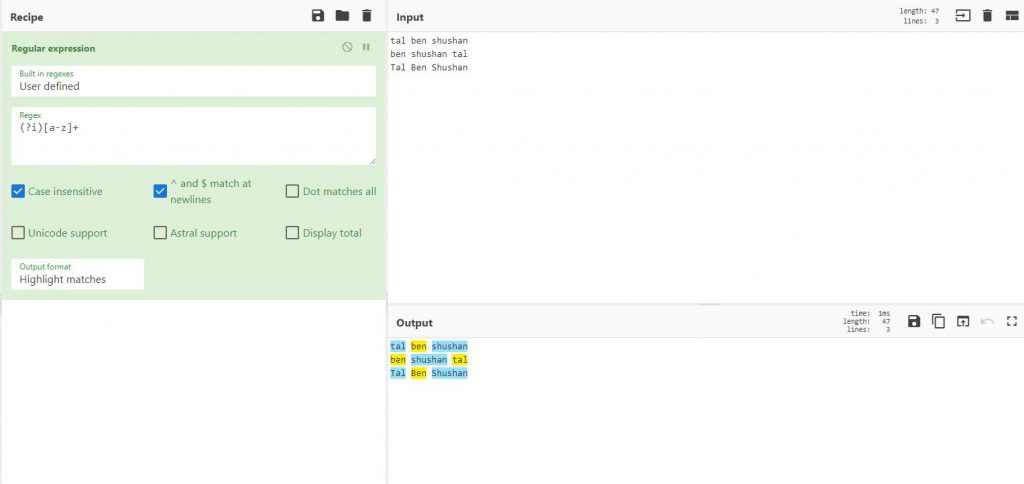
Inline Modifiers
הם יכולים לשנות את הפעולה שאתם מבצעים, לדוגמה , אם הייתי רוצה לסמן את כל האותיות מ a-z אבל שהוא יתייחס גם לאותיות גדולות וקטנות, נוכל להשתמש ב i
(?i)[a-z]+
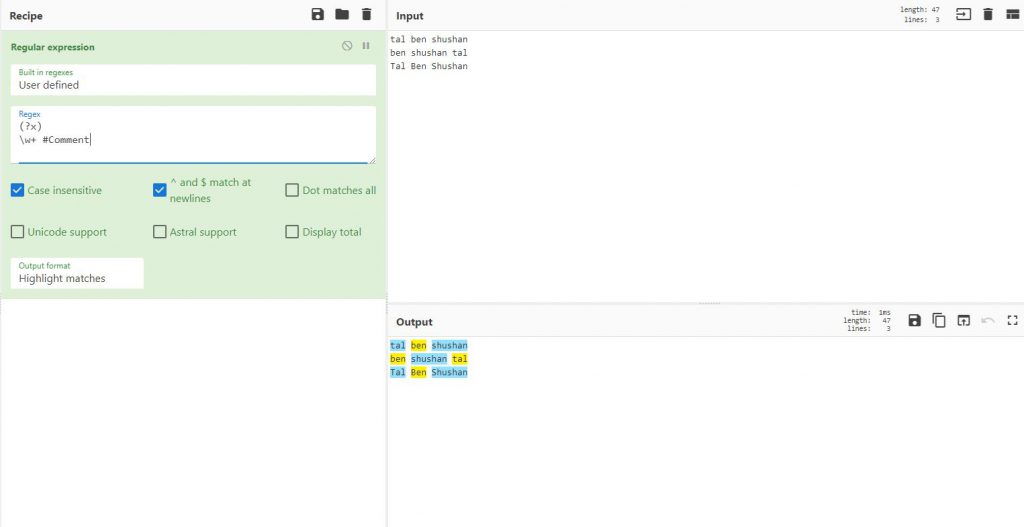
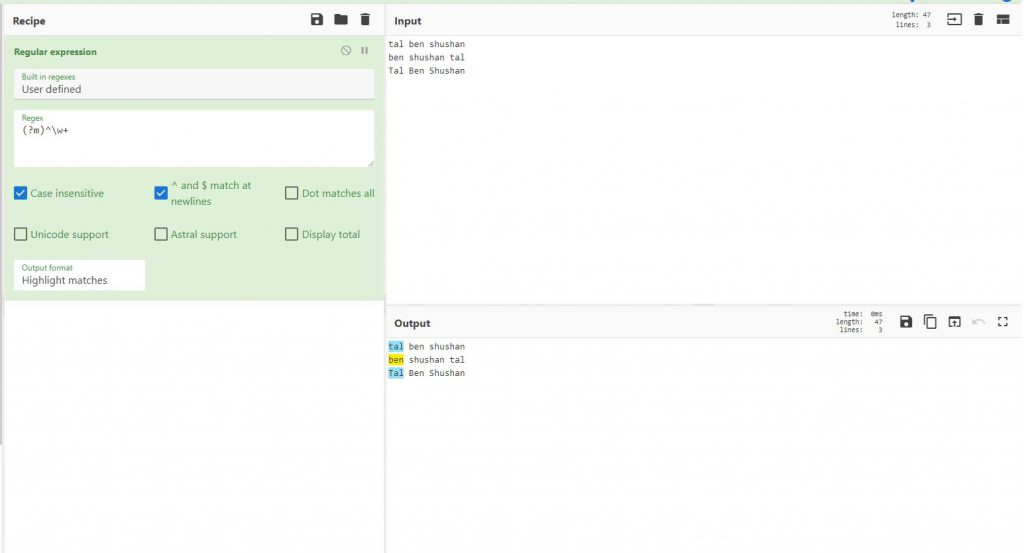
נניח והייתי רוצה לסמן את כל המילים שבהתחלה, אבל את כולם ולא רק את הראשון, הייתי משתמש ב^ anchor אבל הוא היה מסמן רק את המילה הראשונה ולא את כל המילים הראשונות
ולכן אשתמש ב
(?m)^\w+
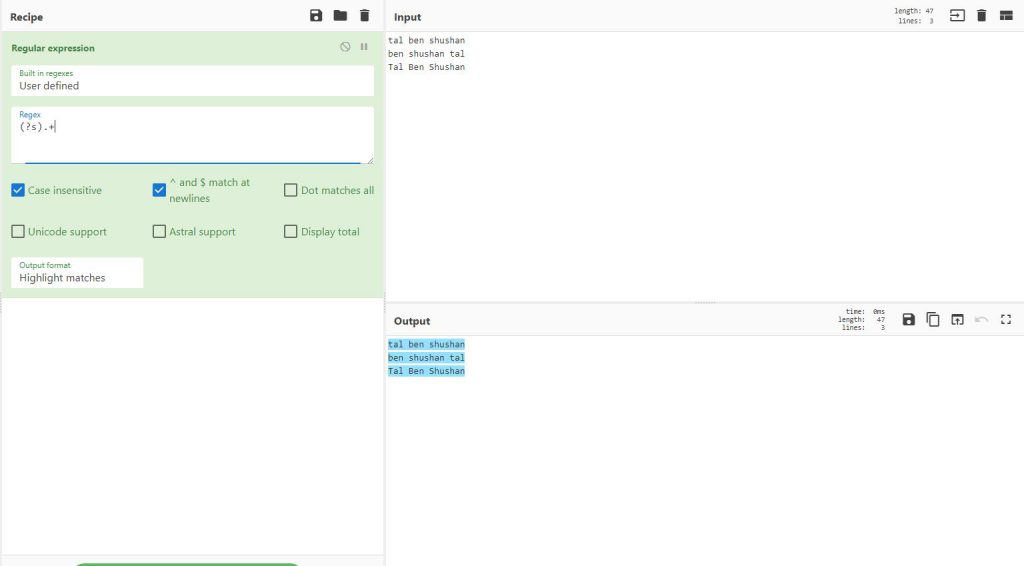
הModifier הבא הוא היכולת שלנו לסמן הכל, נניח ואני רוצה לסמן את כל הטקסט הקיים כולל רווחים, הייתי משתמש ב+. אבל הוא היה מסמן לי כל שורה בנפרד
אם אני רוצה לסמן את הכל כולל רווחים אבצע זאת כך
ה Modifier הבא הוא היכולת להפריד בין "הפקודות" או החיפושים של regex ובנוסף להוסיף "הערה" כך ניתן לכתוב את החיפוש ולציין מה כל דבר מחפש ואחרי זה בקלות רבה לקרוא את השאילתא שבצעתם