
{kind=link}
Data Deduplication
או בקיצור Dedup
עולם ה Storage הולך וגדל, הדרישה לנפחים עולה ועולה, נכון עלות HD היום יחסית נמוכה לנפחים גדולים כמו 4TB או יותר, אבל היום עם מעבר לא קטן לSSD על מנת לשפר את הביצועים אשר מגיע בנפחים קטנים יותר מHD רגיל ולכן ניסו חברות הכוננים הקשיחים בעולם הפרטי להוציא את ה SSHD או SSDHD כונן היברידי המשלב בין השניים.
עסקים גדולים או קטנים שבהתחלה לא השתמשו בהרבה נפח, היום הגיעו למצב בו כמות המידע שהם מחזיקים היא עצומה ולא רק, עסקים בינוניים וגדולים התחילו להעביר את כל התיקים \ מסמכים מודפסים שלהם לחברות סריקה על מנת להיפטר מה"דף" ולהעביר הכל למחשב (במקרה זה ה DD אינו כל כך יעיל) והצריכה לנפח עצום עולה ועולה… ולכן בשרתים המחזיקים מסמכים של המשתמשים, מכל הסוגים הגיעו לשיטה הנקראת Data Deduplication שיטה זו אומרת כי כל קובץ בכונן אשר יש לו תאום "יאוחד" מה הכוונה?
אם הקובץ בבינארי מתחיל ב 110010010000100 וקיים קובץ כזה נוסף השונה במעט לדוגמה 110010010001111 האדום מסמן שהקובץ בחלקו תואם ויאוחסן באופן מוגדר על System Volume Information folder שיגדיר כאילו יש עותק אחד של הקובץ, הכוונה היא שבגלל שה blocks של שני הקבצים או יותר דומה הblock ישונה לנתיב stubs שמקשר אל הנתונים ובכך כאשר תפעילו קובץ מסוים חלקו או כולו לא יהיו "באמת" במיקום בו אתם נמצאים אלה ב"מאגר" ובקובץ עצמו יש נתיב שמכוון אל אותו ה"מאגר" ובכל כל הקבצים הדומים יפנו אל אותו מיקום 1 ובכך חוסכים 3 קבצים שתופסים נפח בכונן.
על פי התפיסה אם יש 3 קבצים הזהים אותו הדבר, כאילו ייחשב הדבר לקובץ 1 ולכן כל 3 הקבצים יתפסו רק 1/3 מהנפח המקורי של כל שלושתם הקבצים יחד
אז כיצד מגדירים Data Deduplication? בקלות למדי…
נבצע זאת על כונן קשיח , אות הכונן E
למטרת ההבנה והלמידה הכנסתי קבצים מסוגים שונים לתיקייה 1 ואותם הקבצים לתיקייה 2

2 תיקיות אותם קבצים, אבל שרת קבצים עם נפח של 4TB יכול לחולל לכם מהפכה בחסכון
נכנסתי לServer Manager ->Manage -> Add Roles
נפתח את הלשונית File and stoarge Services
נסמן ב V את Data Deduplication

התקינו את DD
נפתח שוב את Server Manager נלחץ בצד שמאל על File and stoarge Services
נלחץ על Volumes
קליק ימני על הכונן בו תרצו לבצע את ה Data Deduplication
ואז לחצו על Configure Data Deduplication
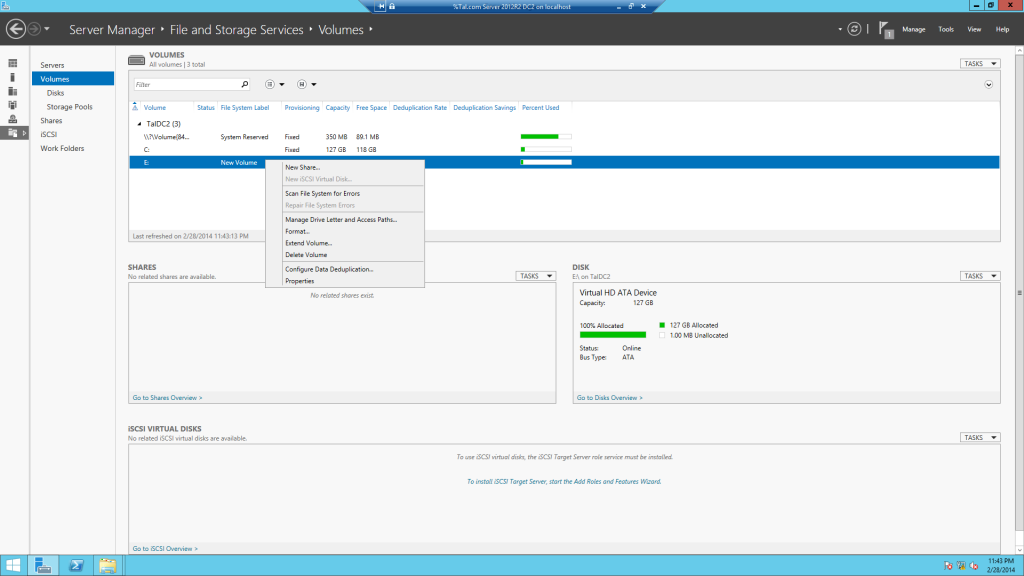
קליק ימני על הכונן הרצוי
נסמן את General Purpose file server – ההגדרה הרגילה
Deduplication files older then – בצע Deduplication רק לקבצים הישנים יותר משבוע והחדשים אל תבצע עדיין Deduplication , אצלי הגדרתי 0 שאומר לו לבצע Deduplication לכל הקבצים ללא קשר למתי נוצרו
ב Exclude ניתן להכניס סיומות של קבצים שאתם לא רוצים שיבוצע בהם Deduplication
בכפתור למטה set Deduplication Schedule ניתן להגדיר מתי יבוצע Deduplication
נלחץ לאחר מכן OK
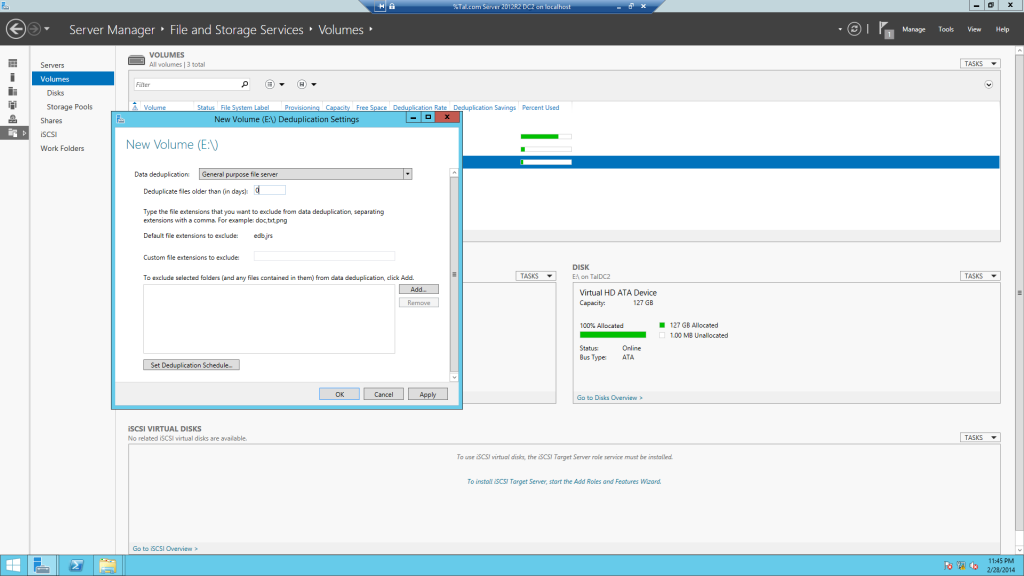
בצעו כמו בתמונה
לאחר כמה שעות (שיבוצע ה Deduplication) ניתן לראות שהוא הצליח לחסוך 3.49GB המהווים 43%
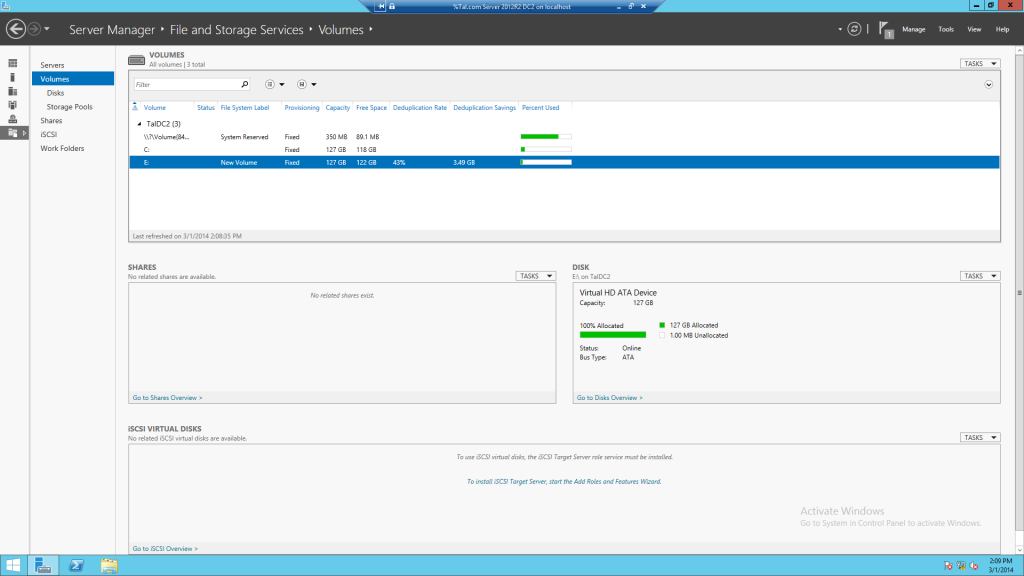
זה לוקח זמן, ולכן לא תראו כל שינוי באותו הרגע
ניתן להגדיר אפשרות נוספת שהיא ה VDI המותאמת לCluster Shared Volumes וגם VHD הנמצאים בכונן שמבצעים לרוב על Clusters וביצוע של Hyper-v Moving
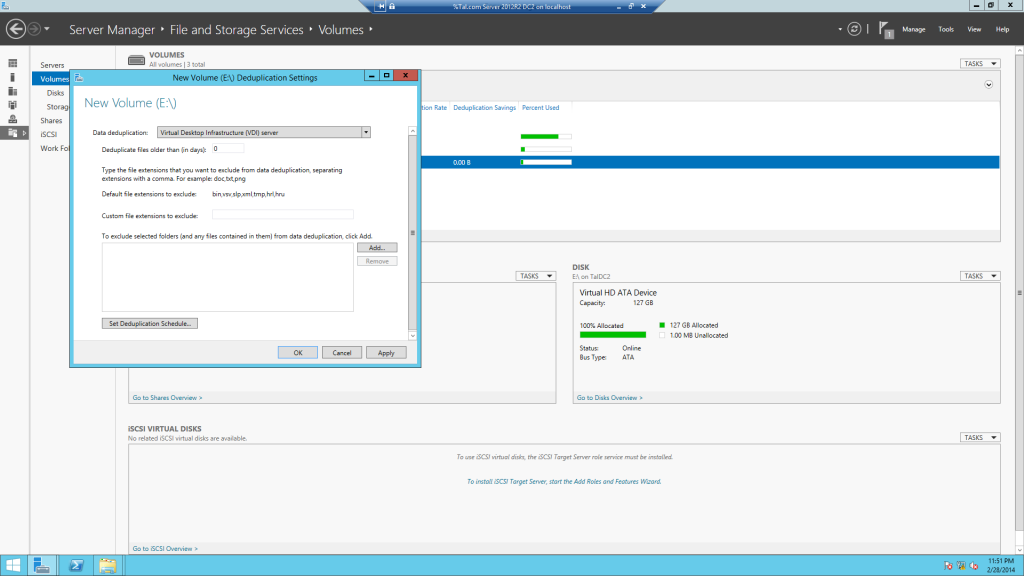
VDI